
12. Juni 2026
Same Same but Different: Die Anatomie der Gleichförmigkeit im KI-Design
Gib einem Agenten deine Art Direction, und er baut trotzdem die Seite, die alle anderen auch bekommen haben. Das ist kein Geschmacksproblem, das ist ein Statistikproblem. Ein Blick auf die Geschichte der Design-Konvergenz, die Forschung, die erklärt, warum Prompts ihr nicht entkommen, und die Hebel, die wirklich zurück zur eigenen Identität steuern.
Sascha Becker
Author23 Min. Lesezeit

Lass einen Agenten eine Website für dich bauen, und man sieht es. Nicht, weil sie schlecht ist. Weil sie vertraut ist. Der dunkle Hero mit dem radialen Glow. Die zentrierte Headline in Inter. Die zwei Buttons, einer gefüllt, einer umrandet. Die drei Feature-Cards mit den kleinen Icons. Das Indigo. Immer das Indigo.
Böse Zungen nennen es AI Slop. Der Begriff trägt schwer, aber die Beobachtung darunter ist real: KI-generierte Interfaces tragen einen statistischen Fingerabdruck, der sie auf den ersten Blick identifizierbar macht, so wie ein Stockfoto auf den ersten Blick identifizierbar ist. Und die üblichen Reaktionen darauf sind entweder Resignation ("so sieht KI eben aus") oder der Essay, den ich mich weigere zu schreiben: die zehntausendste Meditation darüber, dass KI keine künstlerische Seele hat.
Beide Reaktionen sind falsch, weil beide die Gleichförmigkeit als Mysterium oder als Metaphysik behandeln. Sie ist keins von beidem. Sie ist ein Mechanismus. Die Konvergenz ist messbar, die Ursachen sind publiziert, die Psychologie dahinter ist älter als das Web, und die Forschung daran, wie man wieder herauslenkt, bewegt sich schnell. Dieser Post ist der Versuch, das Thema so zu behandeln, wie es das verdient: als System mit Teilen, die man benennen kann.
Diese Gleichförmigkeit haben wir schon mal gebaut
Das aktuelle Limbo fühlt sich neu an, aber es ist die dritte Konvergenzwelle in lebender Erinnerung, und die beiden vorherigen lehren uns das meiste von dem, was wir brauchen.
| Welle | Jahre | Treiber | Wie alles aussah |
|---|---|---|---|
| Material-1-Apps | 2014 bis 2018 | Eine Designsprache, kaum Theming | Weiße Flächen, FAB, Drawer, Markenfarbe als Akzent |
| Template-Web | 2010 bis 2019 | Frameworks, CMS-Templates, Responsive Grids | Hero, drei Cards, Testimonial-Band, Footer-Spalten |
| Agentische Interfaces | 2023 bis heute | Geteilter Trainingskorpus, geteilte Scaffolds | Dunkler Glow-Hero, Inter, Indigo-Buttons, Card-Grid |
Google kündigte Material Design im Juni 2014 auf der I/O an, und es war wirklich gut: eine kohärente Physik aus Flächen, Bewegung und Tiefe, die Android aus seiner Holo-Wildnis rettete. Aber die erste Version kam mit wenig Raum für Abweichung, und der Pfad des geringsten Widerstands führte überall an denselben Ort. Apps legten ihre Persönlichkeit ab, zugunsten weißer Hintergründe und einer einzigen Akzentfarbe. Die Kritik wurde laut genug, dass Googles Refresh von 2018, Material Theming, explizit als Antwort darauf gerahmt wurde, dass Apps zu ähnlich aussahen1. Was als Einladung zum Handwerk gedacht war, wurde zur Vorlage für Uniformität, und Google brauchte vier Jahre neues Tooling und neue Guidelines, um das teilweise zurückzudrehen. Apple fuhr dasselbe Experiment mit lockererer Leine: Die Human Interface Guidelines ließen mehr Raum für Art Direction, und die iOS-Apps jener Ära variierten tatsächlich stärker. Aber die Flat-Design-Welle, die iOS 7 im Jahr 2013 lostrat, produzierte ihr eigenes Meer austauschbarer weißer Screens. Mehr Freiheit, derselbe Attraktor, langsamere Drift.

Das Web brauchte nicht mal eine Designsprache, um zu konvergieren. Es brauchte Templates, Frameworks und ein Jahrzehnt. Der sauberste Beleg ist eine CHI-Studie von 2021 von Sam Goree und Kollegen an der Indiana University, die Computer Vision über mehr als 227.000 Screenshots von rund 10.000 Websites aus den Jahren 2003 bis 2019 laufen ließen. Bis etwa 2007 wurden Websites tatsächlich vielfältiger. Dann drehte der Trend, und zwar hart: Die durchschnittliche Layout-Distanz zwischen Websites fiel zwischen 2010 und 2019 um 44 Prozent2. Die Treiber, die ihre Interviewpartner nannten, sind eine vertraute Liste: geteilte Frameworks und Libraries (die Studie fand, dass Library-Adoption stark mit visueller Ähnlichkeit korreliert), Responsive Design, das Layouts auf stapelbare Spalten zusammenfaltet, CMS-Templates sowie SEO- und Conversion-Praktiken, die diktieren, was above the fold steht.
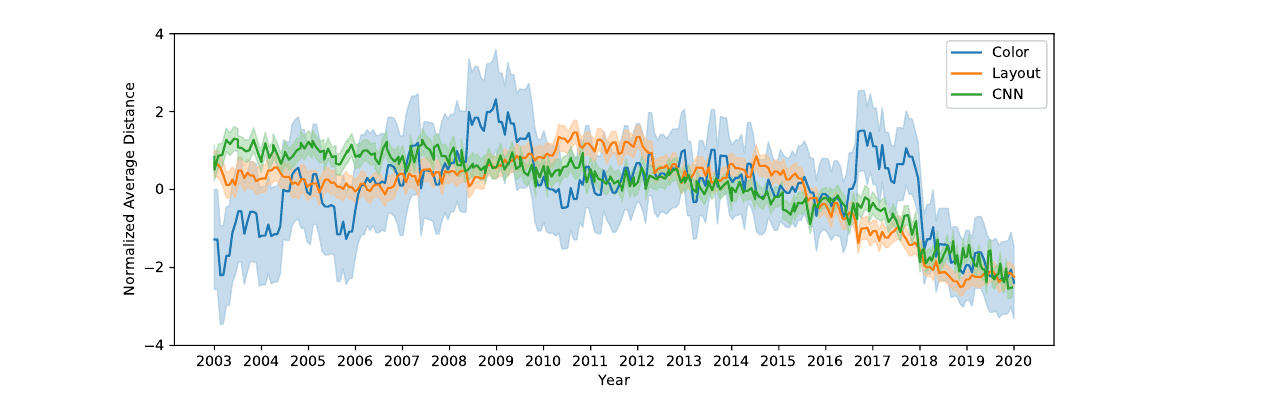
Boris Müller hatte dasselbe 2018 bereits von der Designerseite aus diagnostiziert, in seinem Essay über die visuelle Müdigkeit des Webs: Templates sind content-agnostisch, und content-agnostische Form ist das Gegenteil von Design, weil die tiefe Verbindung zwischen Form und Inhalt konstruktionsbedingt gekappt ist3.
Halte die Jahreszahlen fest. Das Web konvergierte dramatisch zwischen 2010 und 2019. In diesem Loop steckte keine generative KI. Was auch immer gerade passiert: Erfunden hat die KI es nicht.
Der Durchschnitt ist schön, wörtlich
Warum konvergiert Design überhaupt, auch ohne eine Maschine, die schiebt? Weil das menschliche visuelle System Typikalität belohnt, und zwar unterhalb der Ebene von Meinung.
Psychologen nennen die zugrunde liegende Erklärung Processing Fluency: Je leichter ein Reiz zu verarbeiten ist, desto mehr mögen wir ihn, und Vertrautheit, Symmetrie und Prototypikalität machen die Verarbeitung allesamt leichter4. Der Effekt zeigt sich so zuverlässig, dass er einen eigenen Namen hat, Beauty-in-Averageness: Prototypen werden als attraktiver bewertet, und Experimente, die dem Effekt nachgehen, zeigen, dass Fluency die vermittelnde Arbeit leistet. Durchschnittliche Dinge sind im Wortsinn leicht für den Kopf5.
Deshalb passierte jede Konvergenzwelle vor der KI. Eine Designerin testet zwei Layouts im A/B-Test, und das vertrautere konvertiert besser, weil Besucher es schneller parsen. Ein Gründer wählt das Template, das sich "professionell anfühlt", also das, das den letzten hundert Seiten ähnelt, denen er vertraut hat. Raymond Loewy hat die ganze Dynamik vor Jahrzehnten in einen Slogan gepresst: most advanced, yet acceptable. Neuheit verkauft sich nur bis an den Rand der Vertrautheit.
Gleichförmigkeit ist also kein Versagenszustand der Designkultur. Sie ist ein Attraktor, in den Designkultur immer dann fällt, wenn die Kosten der Abweichung steigen oder die Belohnung für Typikalität wächst. Jedes System, das auf unmittelbare menschliche Zustimmung optimiert, driftet zum Prototyp. Merk dir diesen Satz, denn gleich begegnen wir einer Trainings-Pipeline, deren ganzer Job es ist, auf unmittelbare menschliche Zustimmung zu optimieren.
Die Maschine des Mittelwerts
Jetzt der KI-Teil, und der Grund, warum härteres Prompten dich nicht herausholt.
Ein Sprachmodell ist ein komprimiertes statistisches Porträt seines Trainingskorpus. Beim Generieren sampelt es aus einer Wahrscheinlichkeitsverteilung über Fortsetzungen, und die sicherste Wahrscheinlichkeitsmasse sitzt nahe am Modus: der typischsten Art, wie das Internet je eine Landingpage gebaut hat. Bei Basismodellen ist diese Verteilung tatsächlich ziemlich breit. Die Verengung kommt später, und wir wissen wo, denn Forscher haben die Pipeline Stufe für Stufe auseinandergenommen.
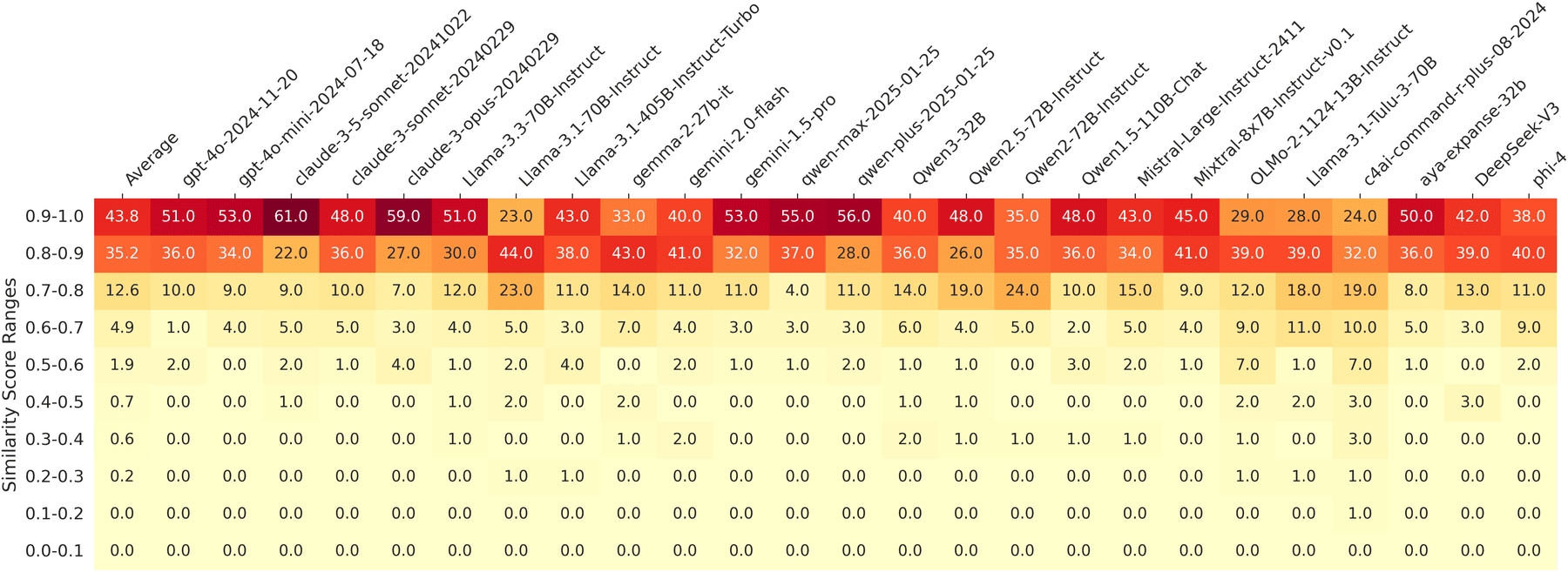
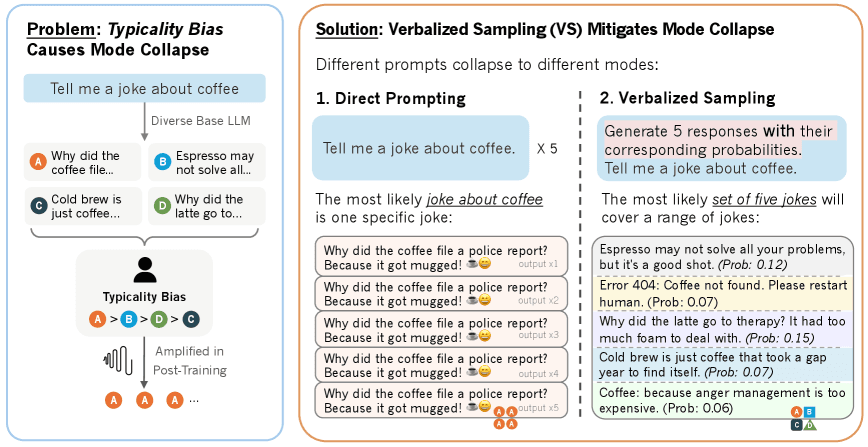
Robert Kirk und Kollegen zeigten auf der ICLR 2024, dass RLHF, die Alignment-Stufe, in der Modelle auf menschliche Präferenzen getunt werden, die Output-Diversität gegenüber Supervised Fine-Tuning substanziell reduziert, über Modelle und Diversitätsmetriken hinweg. Sie beschreiben es als direkten Trade-off: Alignment kauft Generalisierung und bezahlt mit Vielfalt6. Ein Paper von Stanford und Northeastern gab 2025 der Wurzel einen Namen: Typicality Bias. Menschliche Annotatoren, gefragt, welchen von zwei Outputs sie bevorzugen, wählen systematisch den vertrauteren, flüssigeren, prototypischeren, genau wie es die Fluency-Literatur vorhersagt. Dieser Bias fließt ins Reward-Modell, und das Reward-Modell bringt dem LLM dann bei, dass der Modus das ist, was Menschen wollen. Die Autoren zeigen, dass diese Zuspitzung selbst mit einem perfekten Reward-Signal bestehen bleibt7.
Lies das noch mal, denn es ist der Schlussstein dieses ganzen Themas. Derselbe kognitive Bias, der von Menschen gebaute Websites über A/B-Tests und Template-Marktplätze konvergieren ließ, wurde in eine Reward-Funktion destilliert und in industriellem Maßstab angewendet. Mode Collapse ist keine fremdartige Maschinenpathologie. Es ist Beauty-in-Averageness mit Trainingsbudget.
Und das Ergebnis ist längst nicht mehr anekdotisch. Ein NeurIPS-Paper von 2025 führte Infinity-Chat ein, einen Datensatz aus 26.000 echten offenen Nutzeranfragen, und evaluierte mehr als 70 Modelle darauf. Der Befund bekam einen Best Paper Award und einen einprägsamen Namen, den Artificial-Hivemind-Effekt: Einzelne Modelle wiederholen sich, und, schlimmer, verschiedene Modelle produzieren einander frappierend ähnliche Outputs. Frag siebzig Modelle, bekomm eine Ästhetik8.
Die Homogenisierung pflanzt sich dann in menschliche Arbeit fort. In einem großen Experiment, publiziert in Science Advances, schrieben Autoren mit KI-generierten Ideen Geschichten, die Juroren als kreativer bewerteten, mit den größten Zugewinnen bei den am wenigsten kreativen Schreibern. Aber die KI-gestützten Geschichten waren einander messbar ähnlicher als die ohne Hilfe geschriebenen. Die Autoren nennen es ein soziales Dilemma: Individuell stehst du mit der Hilfe des Modells besser da, kollektiv schrumpft der Pool an Neuem9. Eine Studie auf der Creativity & Cognition 2024 fand dieselbe Form beim Ideenfinden: Nutzer, die mit ChatGPT brainstormten, produzierten über Nutzer hinweg semantisch weniger unterscheidbare Ideen als die mit einem Nicht-LLM-Kreativtool, und fühlten sich für das Ergebnis weniger verantwortlich10. Und eine ICLR-Studie von 2024 zum Co-Writing fand das verräterische Detail: Essays, die mit einem feedback-getunten Modell geschrieben wurden, zeigten signifikant reduzierte inhaltliche Diversität, Essays mit dem Basismodell nicht. Die verengende Kraft ist nicht das Sprachmodell. Es ist das Alignment11.
Zwei weitere Teile vervollständigen die Maschine. Erstens, Monokultur: Wenn viele Entscheider einen Algorithmus teilen, korrelieren die Ergebnisse über das ganze Ökosystem, eine Dynamik, die Kleinberg und Raghavan für Hiring formalisiert haben und die Bommasani und Kollegen empirisch für geteilte Modelle und Datensätze bestätigten1213. Im Wesentlichen designt die gesamte Branche jetzt durch drei oder vier Frontier-Modelle. Die Korrelation ist kein Risiko. Sie ist die Versuchsanordnung. Zweitens schließt sich der Loop: KI-generierte Seiten gehen live, werden gescrapt und in den nächsten Trainingskorpus gefaltet. Das Nature-Paper zu Model Collapse zeigte, was wahlloses rekursives Training mit einer Verteilung macht: Die Ränder verschwinden zuerst, unumkehrbar14.
In den Rändern wohnt die Identität
In Verteilungsbegriffen sind die schräge persönliche Seite, die handgeletterte Navigation, das Portfolio, das das Grid absichtlich bricht: Randereignisse. Selten per Definition, unterrepräsentiert in jedem Korpus, und das Erste, was rekursives Training erodiert. Die Gleichförmigkeitsmaschine greift Identität nicht an. Sie vergisst sie einfach, einen Trainingslauf nach dem anderen.
Warum deine design.md dich nicht retten kann
Der Standardrat lautet, bessere Art Direction in den Kontext zu schreiben: eine design.md, ein Brand-Voice-Dokument, ein Stapel Adjektive in der CLAUDE.md. Ich mache das. Du vermutlich auch. Es hilft weniger, als es sollte, und der Verteilungsblick erklärt exakt, warum.
Ein Prompt erweitert die Verteilung des Modells nicht. Er konditioniert sie. Du wählst eine Region dessen aus, was das Modell ohnehin enthält, und dann füllt der Prior jede Entscheidung, die du nicht explizit getroffen hast. Eine Landingpage besteht aus tausenden Mikroentscheidungen: Spacing-Rhythmus, Gewichtskontrast, Eckenradien, wie eine Sektion öffnet, was ein Empty State sagt. Deine design.md legt vielleicht dreißig davon fest. Die anderen tausenden kommen aus dem Modus.
Schlimmer noch: Die Wörter, mit denen du sie festlegst, sind selbst das Vokabular des Modus. "Clean, modern, minimalistisch, mutig, mit Persönlichkeit" ist kein Fingerabdruck, es ist die statistisch dichteste Region allen Design-Schreibens im Internet. Jedes Brand-Dokument sagt das. Wer auf die häufigsten Adjektive des Korpus konditioniert, landet in den häufigsten Designs des Korpus, jetzt in deiner Markenfarbe. Same same, but different. Und wenn du das Modell die design.md überhaupt erst hast schreiben lassen, hast du den Modus auf den Modus konditioniert. Das Dokument, das deine Identität kodieren sollte, ist selbst ein Sample aus der Verteilung, der du zu entkommen versuchst.
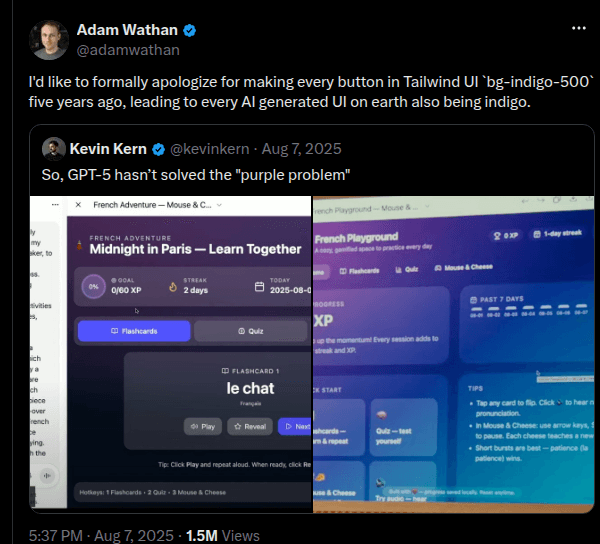
Die Mechanik wird komisch konkret. Im August 2025 entschuldigte sich Tailwind-Schöpfer Adam Wathan öffentlich dafür, fünf Jahre zuvor jeden Button in Tailwind UI bg-indigo-500 gemacht zu haben, was dazu geführt habe, dass "jedes KI-generierte UI auf der Erde ebenfalls indigo ist"15. Er hat gescherzt, und er hatte recht. Ein Default in einer populären Komponentenbibliothek, wiederholt über Millionen Tutorials und Repos, wurde zu einer hochwahrscheinlichen Tokensequenz, und jetzt greift eine ganze Generation generierter Interfaces nach derselben Farbe, wie Wasser nach dem tiefsten Punkt greift. Dieselbe Schwerkraft wirkt auf Stack-Ebene, wo jeder Coding-Agent auf React, Tailwind und shadcn/ui konvergiert, egal von welchem Anbieter; das habe ich in einem eigenen Post auseinandergenommen, und der Mechanismus ist identisch, nur eine Schicht tiefer.
Deshalb fühlt sich "schwere Art Direction in der claude.md" an, als würde sie dich einen schmalen Pfad hinunterzwingen, den andere auch schon gegangen sind: Genau das tut sie. Der Pfad war gepflastert, bevor du ankamst. Anweisungen wählen zwischen existierenden Straßen. Sie bauen keine neuen.
Die Forschung am Zurücklenken
Hier kommt der ermutigende Teil, und der Grund, warum dieser Post keine weitere Klage ist. Mode Collapse stellt sich heraus, zumindest teilweise, als Interface-Problem, nicht als Fähigkeitsverlust. Die Diversität steckt noch im Modell. Die Frage, an der gearbeitet wird, auf vier verschiedenen Ebenen, ist, wie man sie wieder herausbekommt.
Auf der Decoding-Ebene. Die oben erwähnte Arbeit zu Verbalized Sampling ist das praktischste Ergebnis des letzten Jahres. Statt nach einer Antwort zu fragen, lässt du das Modell eine Verteilung verbalisieren: fünf Kandidatenrichtungen, jede mit geschätzter Wahrscheinlichkeit. Weil die Typikalitätszuspitzung bei Einzelantwort-Prompts am stärksten ist, umgeht die Frage nach der Verteilung sie. Die Autoren messen 1,6- bis 2,1-fach höhere Diversität in kreativen Aufgaben, ohne Training, auf Modellen, die du heute schon benutzt7. Daneben stehen Sampler-Methoden wie Min-p-Sampling, ein ICLR-2025-Oral, das die Tokenverteilung dynamisch beschneidet, sodass du heißere Temperaturen fahren kannst, ohne Kohärenz zu verlieren, wobei eine Folgeanalyse bestreitet, wie groß die Gewinne wirklich sind1617.
Auf der Trainings-Ebene. Metas Diverse Preference Optimization verdrahtet den Preference-Tuning-Schritt selbst um: Statt immer die höchstbewertete Antwort zu bevorzugen, wählt es seltene, aber gute Antworten als Chosen-Beispiele und häufige, aber mittelmäßige als Rejected. Das Ergebnis in ihren Experimenten: 45,6 Prozent mehr Diversität bei generierten Persona-Attributen und 74,6 Prozent mehr Story-Diversität bei vergleichbarer Qualität18. Verwandte Arbeiten argumentieren, Homogenisierung müsse aufgabenabhängig behandelt werden: Bei einer Faktenfrage willst du eine Antwort, bei einer ästhetischen eine Streuung, und das Training soll den Unterschied lernen19. Nichts davon liegt in deiner Hand als Nutzer, aber strategisch zählt es: Die Labore behandeln Diversitätsverlust inzwischen als Defekt, gegen den man engineert, nicht als kosmetische Beschwerde.
Auf der Repräsentations-Ebene. Anthropics Arbeit zu Persona Vectors identifiziert Richtungen im Aktivierungsraum eines Modells, die Charaktereigenschaften entsprechen, und zeigt, dass man sie überwachen und steuern kann20. Heute sind die publizierten Traits Dinge wie Sycophancy, nicht visueller Geschmack. Aber die zugrunde liegende Idee, Identität als steuerbare Richtung statt als Prompt-Absatz, ist die interessanteste Langzeitwette auf dieser Liste. Eine Zukunft, in der "der Blick deines Studios" ein Vektor ist, den du auf ein Modell anwendest, so wie Bildleute heute ein Style-LoRA anwenden, das auf der eigenen Arbeit trainiert wurde, ist technisch kontinuierlich mit dem, was schon existiert.
Auf der Workflow-Ebene. Hier ist die HCI-Forschung gerade am nützlichsten. Luminate, ein CHI-System von 2024, lässt das Modell zuerst die Dimensionen eines Design-Raums generieren und ihn dann füllen, sodass der Mensch ein strukturiertes Feld echt verschiedener Optionen erkundet, statt das erste Sample zu akzeptieren21. Eine Studie von 2025 zeigte, dass das Besetzen von LLMs mit unterschiedlichen Personas den Homogenisierungseffekt in der Mensch-KI-Ideenfindung messbar abmildert22. Die gemeinsame Form von all dem: Diversität wird zurückgewonnen, wenn der Mensch aufhört, Konsument einer Antwort zu sein, und Kurator vieler wird.
Deine Identität zurückholen, heute
Die Forschung oben wird die Werkzeuge umbauen. Aber du shippst dieses Quartal, mit den Modellen, die es gibt. Hier ist, was tatsächlich etwas bewegt, geordnet nach Hebelwirkung, und jeder Schritt folgt der Mechanik oben statt wünschendem Prompten.
1. Bau die Identität außerhalb des Modells
Das stärkste Signal, das du einem Agenten geben kannst, ist nicht Prosa, sondern Artefakt. Modelle spiegeln das Projekt, in das man sie setzt, weit treuer, als sie abstrakten Anweisungen folgen. Also entscheide die Designsprache, bevor der Agent ankommt: deine Palette als Tokens, deine zwei Schriften, deine Spacing-Skala, deine Eckenradien, deine Motion-Regeln, kodiert in einer Theme-Datei oder Design-Tokens. Bau den ersten Screen selbst, in welcher Fidelity auch immer du kannst, und lass den Agenten ihn fortsetzen. Du säst die lokale Verteilung. Aus Sicht des Modells wird dein Repo zum Korpus.
2. Ersetz Adjektive durch Artefakte
"Warm und editorial" wählt einen Modus. Ein Screenshot des exakten Magazin-Spreads, den du meinst, wählt einen Punkt. Referenzbilder, Links zu drei Seiten, die das Gefühl teilen, das du willst, deine eigene frühere Arbeit: All das konditioniert das Modell auf etwas, das es aus der Adjektivwolke nicht bekommen kann. Wenn dein Agent Vision unterstützt, schlagen Design-Reviews gegen Screenshots Design-Anweisungen in Prosa, jedes Mal. Zeig auf Dinge. In Wörtern versteckt sich der Modus.
3. Beschränke durch Ausschluss
Der Modus ist ein bekannter Ort, also kannst du ihn benennen und einzäunen. Kein Inter. Kein Indigo, keine Violett-Verläufe. Kein zentrierter Hero mit zwei Buttons. Keine Drei-Card-Feature-Reihe. Kein Glassmorphism. Negative Constraints funktionieren besser als positive, weil sie nicht darauf angewiesen sind, dass das Modell Geschmack interpretiert; sie schneiden die Region höchster Wahrscheinlichkeit weg und zwingen den Sampler, woanders zu landen. Das ist, relativ zur Wirkung, die billigste Intervention auf dieser Liste.
4. Generier breit, wähl schmal
Wende das Verbalized-Sampling-Ergebnis manuell an: Akzeptier nie das erste Design. Verlang fünf Richtungen, denen explizit verboten ist, ein Layout, eine Palette oder eine typografische Idee zu teilen, und lass das Modell sagen, welche die konventionellste ist, dann verwirf genau die zuerst. Dann handle als Art Director: wähle, kombiniere, verwirf. Die Science-Advances-Studie ist klar darin, dass das Modell den Boden anhebt; die Homogenisierungsstudien sind genauso klar darin, dass die Decke, die unverwechselbare Entscheidung, vom kuratierenden Menschen kommt. Geschmack ist der Input, den das Modell nicht liefern kann, weil Geschmack genau das ist, was aus ihm herausgemittelt wurde.
5. Behalt ein handgemachtes Ding pro Seite
Die Ränder sind per Definition handgemacht. Ein gezeichnetes Icon, ein eigener Cursor, eine seltsame 404, ein Chart, das aussieht wie kein anderes, die Navigationsidee, die kein Template hat. Ein einziges wirklich handgefertigtes Element tut mehr für wahrgenommene Identität als hundert Prompt-Tokens, weil es der eine Teil der Seite ist, der beweisbar nicht aus der Verteilung kam. Es ist auch, nicht zufällig, der Teil, den Besucher sich merken.
Was nicht funktioniert
Mehr Adjektive in die design.md stapeln. Nach "etwas weniger Generischem" fragen (du bekommst den Modus mit anderer Akzentfarbe). Das Modell deine Markenidentität von Grund auf erfinden lassen (du sampelst das Ding, dem du entkommen willst). Die Temperatur hochdrehen, bis die Kohärenz bricht. Und dem Modell glauben, wenn es verkündet, das Design sei "einzigartig und unverwechselbar". Prüf mit deinen Augen, so wie du einen PR diffen würdest.
Der Mittelwert ist ein Startpunkt, kein Ziel
Die ehrliche Version des Fazits muss der Maschine geben, was ihr zusteht. Der Modus ist der Modus, weil Menschen ihn im Durchschnitt bevorzugen. Er konvertiert. Er shippt an einem Nachmittag. Für ein internes Tool, einen Prototyp, eine Settings-Seite ist der Durchschnitt kein Defekt, sondern ein Geschenk; niemand braucht ein avantgardistisches Admin-Panel. Die Material-1-Geschichte lehrt dieselbe Lektion von der anderen Seite: Eine starke gemeinsame Baseline hob den Boden eines ganzen Ökosystems, bevor sie die Decke plättete.
Das Problem ist, den Boden mit dem Gebäude zu verwechseln, und dieser Fehler passiert jetzt im Maßstab des gesamten Webs, automatisch, per Default, mit einem Feedback-Loop, der die Alternativen aus zukünftigen Modellen herauserodiert. Die Gleichförmigkeit war immer ein Attraktor. Was sich geändert hat: Ihr zu entkommen hieß früher, einen Trend zu ignorieren, und heute heißt es, einen Prior zu überstimmen.
Aber der Prior lässt sich überstimmen. Die Forschung sagt, die Diversität steckt noch in den Modellen, zurückholbar darüber, wie wir fragen, trainierbar durch bessere Objectives, steuerbar als Vektoren und erkundbar als Design-Räume. Die Geschichte sagt, Konvergenzwellen enden, wenn das Tooling anfängt, Abweichung zu belohnen, so wie es Material Theming und das Web nach Bootstrap irgendwann taten. Und die Praxis sagt, dass Identität heute exakt das kostet, was sie immer gekostet hat: einige Entscheidungen selbst zu treffen, von Hand, bevor die Maschinerie ankommt, und sie zu verteidigen, wenn sie zurückdrückt.
AI-powered statt AI-squashed ist kein Tooling-Feature, auf das du warten kannst. Es ist eine Arbeitsteilung, die du entscheiden musst. Das Modell liefert den Durchschnitt, kompetent und sofort. Du lieferst den Grund, warum sich irgendjemand an die Seite erinnern sollte. Dieser Teil war nie der Job der Maschine, nicht 2014, nicht 2019, nicht jetzt.
Quellen
- Investigating the Homogenization of Web Design: A Mixed-Methods Approach
Goree, Doosti, Crandall, Su (CHI 2021). Computer Vision über 227.000 Website-Screenshots, 2003 bis 2019: Die Layout-Distanz zwischen Seiten fiel in den 2010ern um 44 Prozent, Framework-Adoption korreliert stark mit visueller Ähnlichkeit.
- Why Do All Websites Look the Same?
Boris Müllers Essay von 2018 über die visuelle Müdigkeit des Webs: Templates sind content-agnostisch, und content-agnostische Form kappt die Verbindung zwischen Form und Inhalt, die Design eigentlich ausmacht.
- Processing Fluency and Aesthetic Pleasure: Is Beauty in the Perceiver's Processing Experience?
Reber, Schwarz, Winkielman (2004). Die grundlegende Erklärung, warum leicht zu verarbeitende Reize als schöner beurteilt werden: die Psychologie unter jeder Konvergenzwelle im Design.
- Prototypes Are Attractive Because They Are Easy on the Mind
Winkielman, Halberstadt, Fazendeiro, Catty (2006). Der Beauty-in-Averageness-Effekt, mit Fluency als nachgewiesenem Mediator der Attraktivität prototypischer Reize.
- Understanding the Effects of RLHF on LLM Generalisation and Diversity
Kirk et al. (ICLR 2024). RLHF verbessert Out-of-Distribution-Generalisierung, reduziert aber die Output-Diversität substanziell gegenüber Supervised Fine-Tuning: Alignment tauscht Vielfalt gegen Verlässlichkeit.
- Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity
Zhang et al. (2025). Identifiziert Typicality Bias in menschlichen Präferenzdaten als Wurzeltreiber von Mode Collapse und zeigt, dass die Frage nach einer verbalisierten Verteilung 1,6- bis 2,1-fach mehr Diversität zurückholt, ohne Training.
- Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Jiang et al. (NeurIPS 2025 Best Paper). Über 70 Modelle auf 26.000 echten offenen Anfragen: Modelle wiederholen sich, und verschiedene Modelle produzieren einander frappierend ähnliche Outputs.
- Generative AI enhances individual creativity but reduces the collective diversity of novel content
Doshi, Hauser (Science Advances, 2024). KI-Ideen machen einzelne Geschichten besser, besonders bei weniger kreativen Schreibern, während die Sammlung der Geschichten messbar gleichförmiger wird. Das soziale Dilemma generativer Hilfe.
- Homogenization Effects of Large Language Models on Human Creative Ideation
Anderson, Shah, Kreminski (Creativity & Cognition 2024). ChatGPT-Nutzer produzieren über Nutzer hinweg semantisch weniger unterscheidbare Ideen als Nutzer eines Nicht-LLM-Kreativtools, und fühlen sich weniger verantwortlich dafür.
- Does Writing with Language Models Reduce Content Diversity?
Padmakumar, He (ICLR 2024). Co-Writing mit einem feedback-getunten Modell reduziert inhaltliche Diversität, Co-Writing mit dem Basismodell nicht. Die verengende Kraft ist das Alignment, nicht das Language Modeling.
- Algorithmic monoculture and social welfare
Kleinberg, Raghavan (PNAS 2021). Das formale Argument, dass viele Entscheider mit einem geteilten Algorithmus die Gesamtqualität der Ergebnisse senken können, selbst wenn der Algorithmus individuell überlegen ist.
- Picking on the Same Person: Does Algorithmic Monoculture lead to Outcome Homogenization?
Bommasani, Creel, Kumar, Jurafsky, Liang (NeurIPS 2022). Empirische Belege, dass geteilte Modelle und geteilte Trainingsdaten Ergebnisse über Deployments hinweg homogenisieren.
- AI models collapse when trained on recursively generated data
Shumailov et al. (Nature, 2024). Rekursives Training auf Modell-Output erodiert die Ränder der Verteilung unumkehrbar: Das Seltene, das Seltsame und das Persönliche verschwinden zuerst.
- Adam Wathans Indigo-Entschuldigung
Der Tailwind-Schöpfer entschuldigt sich formell für bg-indigo-500, das dazu geführt habe, dass 'jedes KI-generierte UI auf der Erde ebenfalls indigo ist'. Ein Library-Default, destilliert zu einer globalen Ästhetik.
- Diverse Preference Optimization
Lanchantin et al. (Meta, 2025). Preference Tuning so umverdrahtet, dass seltene, aber gute Antworten gewählt werden: 45,6 Prozent diversere Persona-Generierung und 74,6 Prozent diversere Geschichten bei vergleichbarer Qualität.
- Turning Up the Heat: Min-p Sampling for Creative and Coherent LLM Outputs
Nguyen et al. (ICLR 2025 Oral). Dynamisches Truncation-Sampling für diverseren Output bei hohen Temperaturen, daneben eine kritische Re-Analyse von 2025 (arXiv:2506.13681), die die Größe der Gewinne bestreitet.
- Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Chen et al. (Anthropic, 2025). Charaktereigenschaften als Richtungen im Aktivierungsraum, die sich überwachen und steuern lassen: der Forschungsstrang, der 'Identität als Vektor' am nächsten kommt.
- Luminate: Structured Generation and Exploration of Design Space with Large Language Models
Suh, Chen, Min, Li, Xia (CHI 2024). Das Modell generiert zuerst die Dimensionen des Design-Raums und füllt ihn dann: Exploration statt Akzeptanz.
- Diverse AI Personas Can Mitigate the Homogenization Effect in Human-AI Collaborative Ideation
Studie von 2025, die zeigt, dass das Besetzen von LLMs mit unterschiedlichen Personas der Ideen-Homogenisierung in kollaborativen Settings messbar entgegenwirkt.
- Design Against the Machine
Boris Müller über Design-Lehre mit, und gegen, generative Tools: Man kann eine Technologie nicht von der Seitenlinie aus kritisch bewerten.